(Click here for a Postscript version of this page.)
It is known since Euclid that there exists an infinite number of primes. A very large number of proofs can be found in the litteratures (this is certainly one of the mathematical result with so many proofs).
The way this infinity behaves is a great mathematical question. More precisely, mathematicians defined the function p(x) by the number of prime numbers less or equal than a given value x :
|
One of the mathematical breakthrough of the nineteenth century has been the prime number theorem, proven independantly by Hadamard and De La Vallée Poussin in 1896. Roughly speaking, it states that as x becomes big, p(x) is close to x/log(x) (in other words, a random number x has a "probability" 1/log(x) to be prime).
More precisely, the prime number theorem states that
|
|
|
More information on the prime number theorem will be soon available on this site.
Studing the distribution of primes can be done by sieving numbers. In the ancient times, Eratosthenes described a sieve which permits to compute the prime number less than a given value x. Considering the list of integers from 2 to x, it consists by eliminating from this list the non trivial multiples of the primes less than Öx. The non eliminated values are the prime numbers less than x. This sieve is now classical and was extensively used for example as a distributed projet on the net to compute all prime numbers less than 1016 (see Rensselaer's Twin Primes Computing Effort where a sieve has been used to study twin primes).
Sieves can be used to study statistical data on prime numbers, like counting the number of primes, looking for small and large gaps between consecutive primes, counting the number of twin primes (primes p for which p+2 is also a prime), counting primes with a given form, etc.
The cost of classical sieves are close to linear. For example, the use of the classical Sieve of Eratosthenes to compute p(x) can be done in time O(xloglog(x)). More efficient sieve versions are a little quicker, but the asymptotic cost remains close to linear. A two years distributed computation was necessary for example, to compute a certain family of primes less than 1016 with sieving techniques.
Legendre was the first to suggest a method to compute p(x) without locating all the primes less than x. However, his method was not of immediate utility. The first real breakthrough in the p(x) computation was done by Meissel in 1871, who computed p(108) and later p(109) in 1886, which was a value far beyond the known tables of primes at that time. In 1959, D. H. Lehmer simplified Meissel's method to compute p(1010) using an IBM 701. Bohmann in 1972 computed p(1013). Notice that the old calculations p(109), p(1010) and p(1013) turned out to have slight errors, and the later computations were systematically verified by a second computation with different parameters. In 1985, Lagarias, Miller and Odlyzko improved again Meissel method and obtain an algorithm running in time O(x2/3/log(x)) and memory O(x1/3log2(x)) (see [3]). They obtained the value p(4 ×1016). In 1994 Deléglise and Rivat improved the technique once again [2] and saved a factor log(x) in the time cost (but they lost the same factor on the memory cost). They found higher values : p(1017), p(1018) and later, the values p(1019) and p(1020) with a more efficient implementation by Deléglise.
Recently, Xavier Gourdon (one of the two authors web site) made technical improvement to the Meissel, Lagarias, Miller, Odlyzko, Deléglise and Rivat algorithm (see Computation of pi(x) : improvements to the Meissel, Lehmer, Lagarias, Miller, Odlyzko, Deléglise and Rivat method). As a result, some constant factors have been saved and memory usage is lower (no precise asymptotic study has been made until now). The improvement also permits to distribute a large p(x) computation on several machines with a very low memory exchange (Lagarias, Miller and Odlyzko already considered the problem of distributing the computation in [3] but subsequent memory exchange was needed between the machines), provided a precomputation of cost O(x1/2) is made (a description of the improvements will soon be available on this site). The implementation is a program which permitted to obtain a new p(x) record computation in 2000. The value of
|
The prime number theorem states that p(x) is close to the function
|
|
The known values of p(x) today agree with this estimate (see the table below), and even agree with a more tight estimate. It is in fact not so easy to have an idea of what should be exactly the error term. At the end of the 1930's, Cramer proposed a model [4] to construct conjectures on distribution of prime numbers. The Cramer model suggest that the prime numbers behave like a random sequence with the same growth constraint (in other words, each number n have a probability 1/log(n) to be prime in this model). According to this model, the number of primes almost should almost surely (with probability 1) satisfy the equality
|
|
A result of Littewood show that the function q(x) satisfies
|
Riemann and Gauss believed that Li(x) > p(x) (which is equivalent to q(x) < 0) for every x > 3, and all the computed values of p(x) today satisfy this inequality. However it has been proved by Littlewood in 1914 that q(x) changes its sign infinitely often. In 1933, S. Skewes established that the first change of sign occurs before the impressive number 10k with k = 101034. This bound has been improved in 1966 by R.S. Lehman who gave the bound 101166. Later in 1985, H. Te Riele proved that the first change of sign occurs before x = 6.69 ×10370. The best bound known so far has been obtained in 2000 by Carter Bays and Richard H. Hudson [1] who proved that the first change of sign occurs before x = 1.39822 ×10316. Of course, such a large value is not reachable today, but the function q(x) have large variations in the last table values, suggesting that a change of sign could occur not too far from this zone. The p(x) project could afford the first known value x for which p(x) > Li(x) ! Finding the first change of sign if even more difficult !
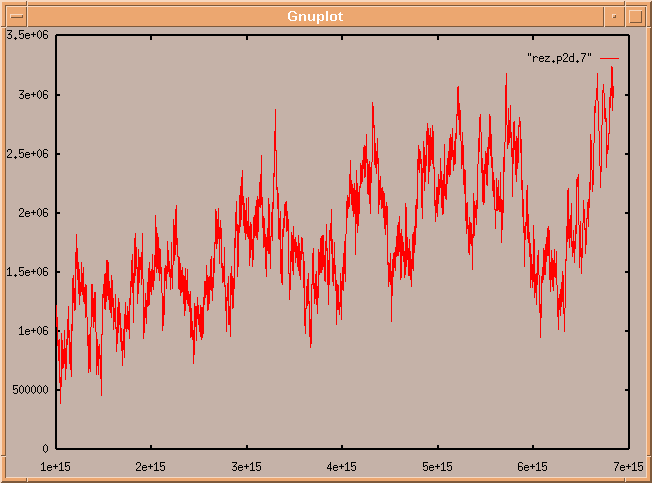
Using a program written by Xavier Gourdon, Patrick Demichel computed a large number of values of Li(x)-p(x) for x between x = 1015 and x = 7×1015 every 1012. As a result, he obtained a graphic view of this function in this range. As expected, the resulting plotted function is very chaotic.
This table of values of p(x) contains the difference with the function Li(x) (third column), the value of the "normalized" Cramer function
|
Remember that the Cramer model implies the conjecture -1 Ł q(x) Ł 1, which is a stronger conjecture than the bound obtained from the Riemann Hypothesis, and that a change of sign of q(x) has not been found yet (see the section Oscillations above).
Note : the following page contains the description of an interesting algorithm to compute the parity of p(x) in time O(Öx log(x)), together with a table of the parity of p(x) for some values of x (this page contains errors in the parity of p(x) for some values of x ł 5×1019; an implementation of the corresponding algorithm was made by Xavier Gourdon and the parities found confirm the values of our table).
A more complete set of values of p(x) is available in our pi(x) table page.
| x | p(x) | Li(x)-p(x) | q(x) | Comments |
| 106 | 78,498 | 129 | -0.209 | |
| 107 | 664,579 | 336 | -0.1809 | |
| 108 | 5,761,455 | 753 | -0.1339 | Meissel 1871 |
| 109 | 50,847,534 | 1,700 | -0.0994 | Meissel 1886 (Corrected) |
| 1010 | 455,052,511 | 3,103 | -0.0594 | Lehmer 1959 (Corrected) |
| 1011 | 4,118,054,813 | 11,587 | -0.0725 | |
| 1012 | 37,607,912,018 | 38,262 | -0.0781 | |
| 1013 | 346,065,536,839 | 108,970 | -0.0723 | Bohmann 1972 (Corrected) |
| 1014 | 3,204,941,750,802 | 314,889 | -0.0678 | Lagarias Miller Odlyzko 1985 |
| 1015 | 29,844,570,422,669 | 1,052,618 | -0.0735 | LMO 1985 |
| 1016 | 279,238,341,033,925 | 3,214,631 | -0.0726 | LMO 1985 |
| 1017 | 2,623,557,157,654,233 | 7,956,588 | -0.0581 | Deléglise Rivat 1994 |
| 1018 | 24,739,954,287,740,860 | 21,949,554 | -0.05177 | Deléglise Rivat 1994 |
| 1019 | 234,057,667,276,344,607 | 99,877,774 | -0.0760 | Deléglise 1996 |
| 1020 | 2,220,819,602,560,918,840 | 222,744,643 | -0.0546 | Deléglise 1996 |
| 2*1020 | 4,374,267,703,076,959,271 | 472,270,046 | -0.0823 | X. Gourdon 2000 Nov |
| 1021 | 21,127,269,486,018,731,928 | 597,394,253 | -0.0471 | X. Gourdon 2000 Nov |
| 2*1021 | 41,644,391,885,053,857,293 | 1,454,564,714 | -0.0816 | pi(x) project, 2000 Dec |
| 4*1021 | 82,103,246,362,658,124,007 | 1,200,472,717 | -0.0479 | pi(x) project, 2000 Dec |
| 1022 | 201,467,286,689,315,906,290 | 1,932,355,207 | -0.0491 | pi(x) project, 2000 Dec |
| 1.5*1022 | 299,751,248,358,699,805,270 | 2,848,114,312 | -0.0592 | P. Demichel, X. Gourdon, 2001 Feb |
| 2*1022 | 397,382,840,070,993,192,736 | 2,732,289,619 | -0.0493 | pi(x) project, 2001 Feb |
| 4*1022 | 783,964,159,847,056,303,858 (*) | 5,101,648,384 | -0.0655 | pi(x) project, 2001 Mar (Current world record) |
(*) Thanks to Leonid Durman who detected that I had written the value of li(4*1022) instead of p(4*1022). The mistake have been corrected.
Thomas Nicely site about twin primes, primes gap, etc. The pages also contain values of pi(x) for x up to 3.1015 every 1012.
Henri Lifchitz page about an interesting algorithm to compute the parity of p(x) in time O(x1/2 log(x)).
numbers, constants and computation